
CodeLoops v0.3.0: Unified Streaming Knowledge Graph


Coding agents often produce messy, unreliable code ("code slop"), and my goal with CodeLoops has been to inch us towards the holy grail: autonomous coding agents. You can get caught up to speed in my original article. Starting as a proof-of-concept, CodeLoops showed early promise with a JSON-based knowledge graph. Now, with version 0.3.0, I’m happy to share a step towards a capable, data-intensive system through the Unified Streaming Knowledge Graph. Sounds pretty badass right? Well my inner software developer cynic will tell you, thats just a superficial way of saying it uses NDJSON and Nodejs streaming APIs... BUT, this feature does transform how CodeLoops handles complex projects and massive amounts of data in your knowledge graph, smoothly.
What’s New in v0.3.0
Earlier versions of CodeLoops used JSON files that loaded entire project graphs into memory. This worked fine for lightweight workflows (like the memory MCP server in the model context protocol repo), but as a power user managing multiple projects, I hit limitations. Large mutable graphs led to data loss and cross-project mix-ups, especially when juggling several coding tasks.
The Unified Streaming Knowledge Graph solves these issues by using NDJSON (knowledge_graph.ndjson) for streaming reads and writes, ensuring low memory usage and safe concurrent operations. Here’s what’s new:
- NDJSON Graph: Stores actor-critic entries as JSON lines, handling large graphs with minimal memory overhead.
- Multi-Project Support: Infers projects from
projectContextpaths, eliminating the need for a separateProjectManager. - Simplified Workflow:
actor_thinkcalls now always trigger critic feedback, stopping agents from dodging critique vianeedsMore: true. - Migration Script: Converts existing JSON files to NDJSON with integrity checks (details below).
- Structured Logging: Uses Pino to log to a
logsdirectory with 14-day retention and daily rotation, improving debugging and traceability.
How to Upgrade
Navigate to your CodeLoops directory:
cd codeloops
Run the migration script:
npx -y tsx scripts/migrations/migrate021_030.ts
Install dependencies:
npm install
Update the repository:
git pull
You’re good to go!
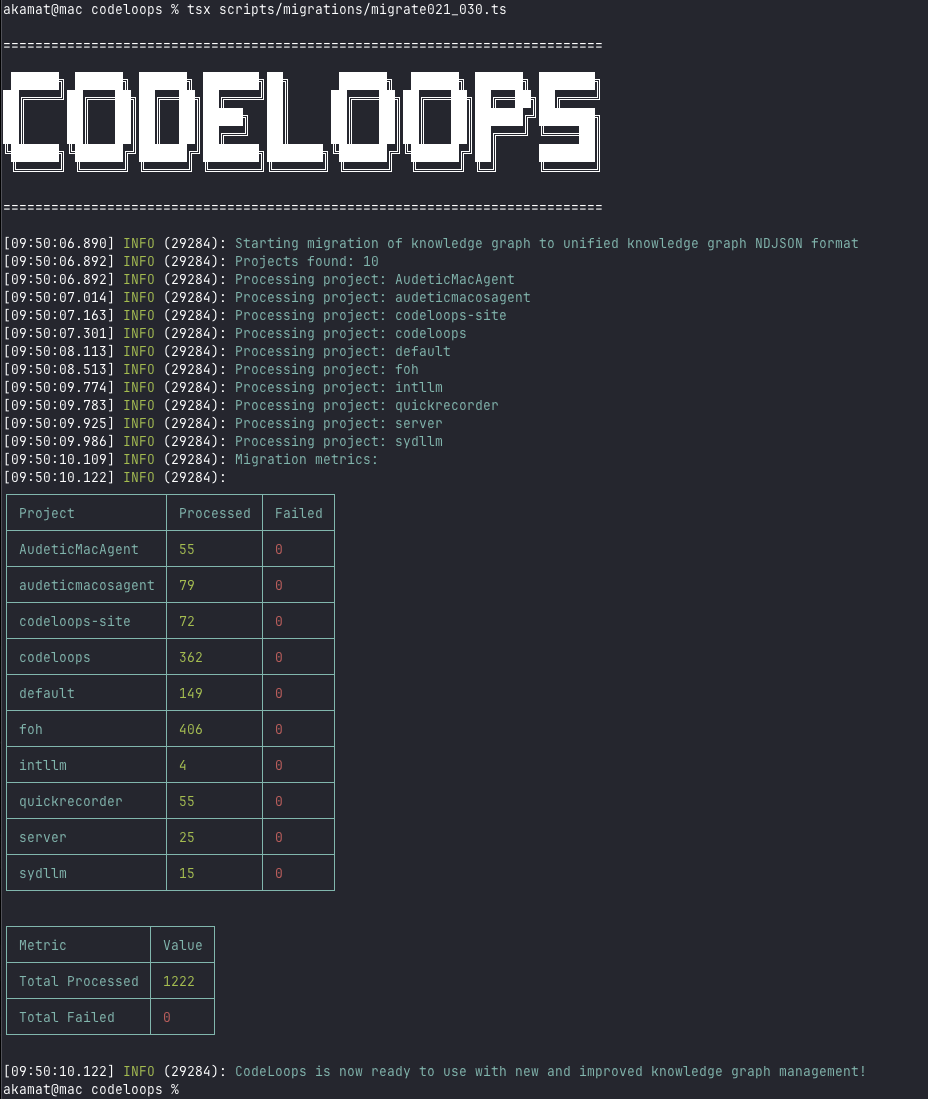
Migration Details
My migration script (scripts/migrations/migrate021_030.ts) converts per-project JSON files (kg.*.json) into a single knowledge_graph.ndjson file. It reads JSON files, extracts project names, enriches entities with project context, and writes them as NDJSON lines. The script includes error handling, logs failed entities to failed_entities.ndjson, and creates backups of original files in a backups directory. Metrics on processed and failed entities are displayed in an ASCII table for clarity.
Why NDJSON and Streams?
NDJSON (Newline Delimited JSON) stores each knowledge graph entry as a single JSON line, perfect for streaming reads and writes. This append-only format is compact, queryable with tools like jq, and maintains data integrity. Node.js streams process entries line-by-line, keeping memory usage low even for massive graphs. The benefits are clear:
- Scalability: Streams manage large datasets with a tiny memory footprint.
- Reliability: File locking ensures safe concurrent writes, essential for multi-agent systems.
- Traceability: Immutable logs preserve task sequences, simplifying debugging.
- Simplicity: A single
knowledge_graph.ndjsonfile handles all projects, with artifact lookups viaDagNode’sartifactsfield. - Future-Ready: NDJSON enables deriving data structures (e.g., artifact lookup tables with checksums) for advanced use cases.
Visualizing the Unified Streaming Log
As my actor and critic agents collaborate, their interactions form sequential entries in knowledge_graph.ndjson. Here’s how it builds:
Empty Log:
knowledge_graph.ndjson
└── {}
Actor Plans Migration Script (2025-05-14 14:00):
knowledge_graph.ndjson
├── [1: Plan Migration: Create script to convert JSON to NDJSON, project: codeloops, artifact: scripts/migrate.ts]
└── {}
Critic Approves Plan (2025-05-14 14:01):
knowledge_graph.ndjson
├── [1: Plan Migration: Create script..., project: codeloops, artifact: scripts/migrate.ts]
├── [2: Approve Plan: Approved, project: codeloops, target: Plan Migration]
└── {}
Each entry adds a line, capturing the sequence from planning to approval and implementation.
Query Visualization
To extract unique project names, it can stream and filter entries:
knowledge_graph.ndjson
├── [1: Plan Migration: project="codeloops", Create script...] ----> Keep
├── [2: Fix UI: project="AudeticMacAgent", Enhance UI icons...] ----> Keep
├── [3: Review Docs: project="codeloops", Review kg_design_v2.md] ----> Skip (seen codeloops)
└── ...
Result: ["codeloops", "AudeticMacAgent"]
State Computation Example
Say we want to create a visual representation of the knowledge graph, where each project is a tray, and each entry is a node in that tray. We can do this again by streaming the data, sorting the entries by project and then return the computed results.
knowledge_graph.ndjson
├── [1: Plan Migration: project="codeloops", Create script...] ----> codeloops tray
├── [2: Fix UI: project="AudeticMacAgent", Enhance UI icons...] ----> AudeticMacAgent tray
├── [3: Review Docs: project="codeloops", Review kg_design_v2.md] ----> codeloops tray
└── ...
Trays:
codeloops(~5MB, 100 nodes):[1: Plan Migration, 3: Review Docs]AudeticMacAgent(~2MB, 50 nodes):[2: Fix UI]
Only relevant entries load, using ~7MB for 150 nodes, with room for further optimization.
All in all...
Version 0.3.0 makes CodeLoops more scalable and reliable, empowering CodeLoops to handle data-intensive tasks as a power user and paving the way for advanced features like derived data structures and remote observability.
Sign up for this blog if you want to be notified of future updates about CodeLoops.



